Leave a Comment
大数据学习
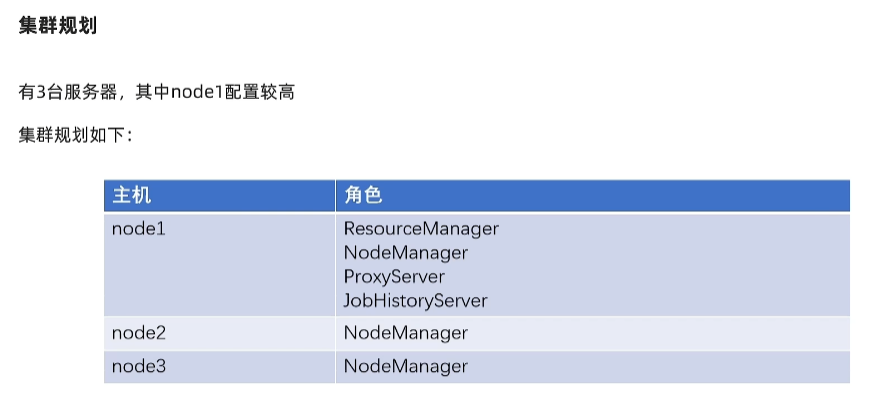
第一步 修改主机名
hostnamectl set-hostname node_1
第二步 修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
如果目录下没有ifcfg-ens33比如我的就是ifcfg-ens160。
可以使用以下代码查看,名称就是文件名
ip addr show打开文件后把BOOTPROTO=dhcp修改为BOOTPROTO=static
新增 IPADDR=”192.168.74.101″,其他依次类推
然后设置网关和子网掩码
IPADDR=192.168.74.101
NETMASK=255.255.255.0
GATEWAY=192.168.74.2
DNS1=192.168.74.2
然后重启服务
systemctl restart network
如果报错则使用
systemctl restart NetworkManager查看配置
ifconfig
如果不对的话 ,可以考虑一下代码一起用。
systemctl disable NetworkManager
systemctl stop NetworkManager
systemctl restart NetworkManager
systemctl enable NetworkManager
ifdown ens160
ifup ens160修改host映射
在windows中设置host
192.168.74.101 node_1
192.168.74.102 node_2
192.168.74.103 node_3
然后用finalshell连接到服务器,如果连接不上可以查看22端口是否打开
你也可以使用以下命令来直接查询端口22的状态:
sudo firewall-cmd --query-port=22/tcp如果此命令返回“yes”,则表示端口22是开放的。如果返回“no”,则表示端口22是关闭的。
请注意,如果你对防火墙进行了更改,并且希望这些更改在系统重启后仍然生效,你需要在执行开放或关闭端口的命令时添加 --permanent 选项。例如,要永久开放端口22,你可以使用:
sudo firewall-cmd --zone=public --add-port=22/tcp --permanent然后,你需要重新加载防火墙配置以使更改生效:
sudo firewall-cmd --reload
# 也可以关闭禁用防火墙
systemctl stop firewalld
systemctl disable firewalld
sudo systemctl status sshd
sudo systemctl start sshd
修改linux的hosts
vim /etc/hosts
192.168.74.101 node_1
192.168.74.102 node_2
192.168.74.103 node_3
为了后续传文件方便,为每个服务器配置免密登录,执行
ssh-keygen -t rsa -b 4096
然后执行
ssh-copy-id node_1 ssh-copy-id node_2 ssh-copy-id node_3
为每个机器创建hadoop用户
useradd hadoop
passwd hadoop
切换到hadoop,su hadoop 然后执行 ssh-keygen -t rsa -b 4096
ssh-copy-id node_1 ssh-copy-id node_2 ssh-copy-id node_3
创建目录 mkdir -p /export/server
然后rz上传
再解压文件
tar -zxvf jdk-17_linux-x64_bin.tar.gz -C /export/server/
cd /export/server/
ln -s /export/server/jdk-17.0.10 jdk
执行vim /etc/profile 然后追加如下代码 , 配置环境变量
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
执行 source /etc/profile 让环境变量生效
cd jdk
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java
ln -s /export/server/jdk/bin/javac /usr/bin/javac
安装hadoop
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar -zxvf hadoop-3.3.6.tar.gz -C /export/server
cd /export/server
ln -s /export/server/hadoop-3.3.6 hadoop
cd hadoop
cd etc/hadoop/
vim workers 配置工作节点
node_1 node_2 node_3
vim hadoop-env.sh 加入以下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
vim core-site.xml 中间插入
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node_1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>vim hdfs-site.xml 中间插入
<configuration>
<property>
<name>dfs.namenode.rpc-address</name>
<value>node-1:8020</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node_1,node_2,node_3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>在主节点创建 /data/nn
mkdir -p /data/nn
所有的都创建/data/dn
mkdir /data/dn
把hadoop文件远程复制到其他节点去
cd /export/server/
scp -r hadoop-3.3.6 node_2:`pwd`/
scp -r hadoop-3.3.6 node_3:`pwd`/
# 在node_2,node_3执行以下命令
ln -s /export/server/hadoop-3.3.6 /export/server/hadoop
配置环境变量
vim /etc/profile
#添加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 执行 source /etc/profile 让环境变量生效授权为hadoop用户
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export对系统进行初始化
su - hadoop
# 格式化
hadoop namenode -format
# 启动
# 一键启动hdfs 集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
由于名字不能有下划线 所以改用- 。如node_1改为node-1 ,切记host中的名字也会影响,所以host也要修改,然后重启,主要原因可能url下划线的问题。
hostnamectl set-hostname node-1
hdfs创建文件夹
hdfs dfs -mkdir -p /itheima/hadoop
# 两种方式都可以创建
hadoop fs -mkdir -p /itcast/bigdata
# 查看路径
hdfs dfs -ls /
# 上传文件 words.txt 到 /itcast
hdfs dfs -put words.txt /itcast
# 查看文件
hdfs dfs -cat /jdk-17_linux-x64_bin.tar.gz
#下载/jdk-17_linux-x64_bin.tar.gz到 ./jdk-17_linux-x64_bin.tar.gz
hdfs dfs -put /jdk-17_linux-x64_bin.tar.gz ./jdk-17_linux-x64_bin.tar.gz
# 复制 -cp
Browse Directory
Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS: Server Error
jdk版本太高了, 重新下载低版本 jdk-11.0.21_linux-x64_bin.tar.gz
tar -zxvf jdk-11.0.21_linux-x64_bin.tar.gz -C /export/server/
rm /export/server/jdk
ln -s /export/server/jdk-11.0.21 /export/server/jdk
cd /export/server/
scp -r jdk-11.0.21 node_2:`pwd`/
scp -r jdk-11.0.21 node_3:`pwd`/
# 哪个版本还是太高了换成了1.8
tar -zxvf jdk-8u401-linux-x64.tar.gz -C /export/server/
cd /export/server/
scp -r jdk1.8.0_401 node_2:`pwd`/
scp -r jdk1.8.0_401 node_3:`pwd`/
rm /export/server/jdk
ln -s /export/server/jdk1.8.0_401 /export/server/jdk
stop-dfs.sh
start-dfs.sh
搞定
配置YARN
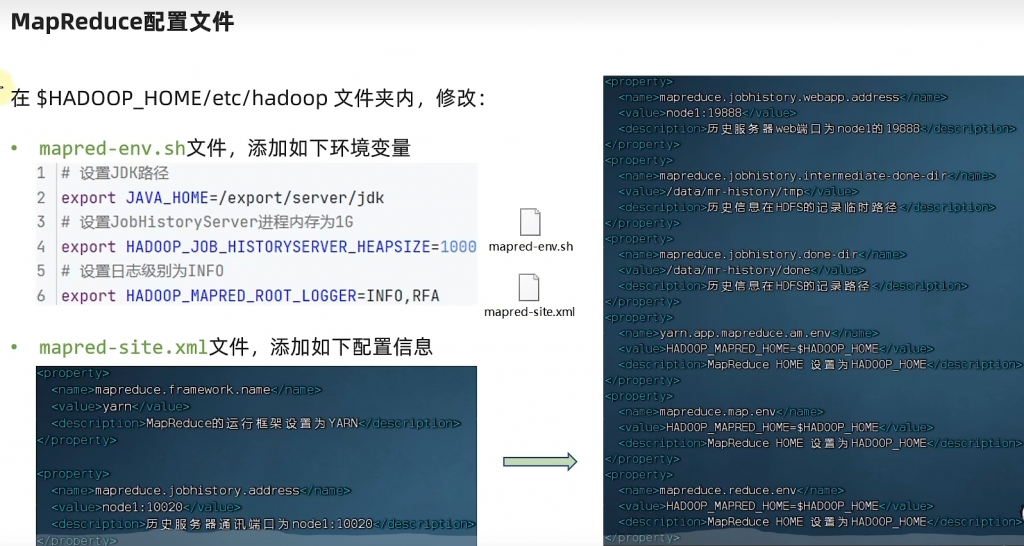
vi /export/server/hadoop/etc/hadoop/mapred-env.sh
# 添加如下代码
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_ROOT_LOGGER =IINFO,RFA
vi /export/server/hadoop/etc/hadoop/mapred-site.xml
# 添加如下代码
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node-1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node-1:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
vim /export/server/hadoop/etc/hadoop/yarn-env.sh
# 添加如下代码
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=/export/server/etc/hadoop
export HADOOP_LOG_DIR=/export/server/logs
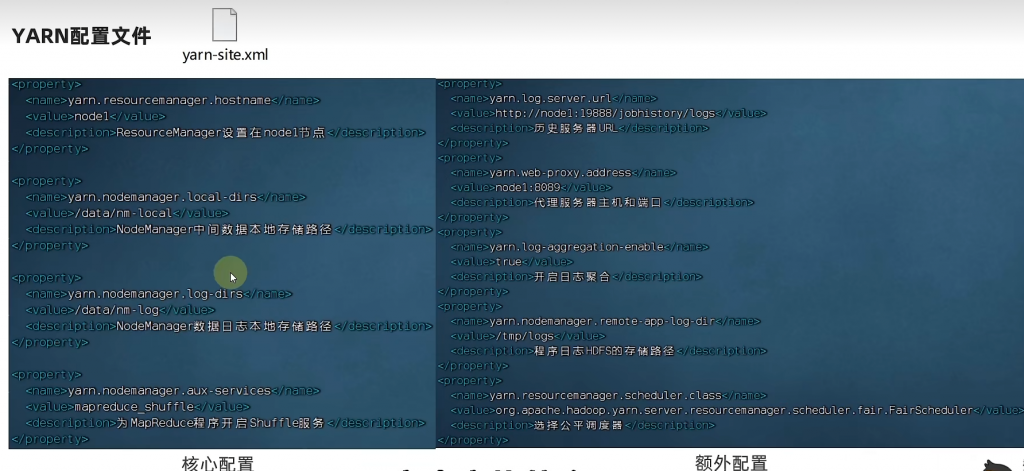
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
# 添加如下代码
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-1</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node-1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node-1:8089</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
</configuration>
# scp 发送到其他服务器
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node-2:`pwd` /
# 启动yarn
start-yarn.sh
# 启动历史服务器
mapred --daemon start historyserver
http://node_1:8088/cluster/nodes
http://node_1:9870/dfshealth.html#tab-overview
su hadoop
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
jps
安装hive
# 首先安装mysql
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# centos8
sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2023
rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el8-7.noarch.rpm
rpm install mysql-server
# yun 安装mysql
yum -y install mysql-community-server
# 启动mysql设置开机启动
systemctl start mysqld
systemctl enable mysqld
#检查mysql服务状态
systemctl status mysqld
# 第一次启动mysql,会在日志中生成随机密码
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p
#设置简单密码
set global validate_password_policy=LOW;
set global validate_password_length=4;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
grant all privileges on *.* to root@"%" identified by 'root' with grant option;
flush privileges;
use mysql;
GRANT ALL ON *.* TO 'root'@'%';
update user set host = '%' where user = 'root' and host='localhost';
GRANT ALL ON *.* TO 'root'@'%';
flush privileges;
USE mysql;
-- 如果你想允许从任何主机登录
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
-- 或者
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
-- 或者,如果 root 用户已经存在并且你只是想更新它的主机设置
UPDATE user SET Host='%' WHERE User='root';
FLUSH PRIVILEGES;
-- 8.0
-- 创建用户(如果尚未存在)并设置密码
CREATE USER 'root'@'%' IDENTIFIED BY 'root';
-- 刷新权限,尽管在大多数情况下不是必需的,因为 MySQL 会自动刷新
FLUSH PRIVILEGES;
-- 授予用户所有数据库的所有权限,并允许用户授予其他用户权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
-- 刷新权限,尽管在大多数情况下不是必需的,因为 MySQL 会自动刷新
FLUSH PRIVILEGES;
systemctl stop mysqld
systemctl start mysqld
设置hadoop用户允许代码其他用户
# vim /export/server/hadoop/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property># 下载hive安装包
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
# 下载hive的mysql驱动包
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/
# com.mysql.cj.jdbc.Driver 驱动下载地址
https://downloads.mysql.com/archives/c-j/
# 配置hive
cd /export/server/hive/conf
cp ./hive-env.sh.template ./hive-env.sh
vi ./hive-env.sh
# 添加 如下变量
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive
export HIVE_AUX_JARS_PATH=/export/server/hive/lib

vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node-1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node-1</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node-1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration># 初始化数据库
# mysql中新建数据
create database hive charset utf8;
# 修改mysql配置 , 添加bind-address
vi /etc/my.cnf.d/mysql-server.cnf
bind-address=0.0.0.0
systemctl restart mysqld
# 服务器中执行
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
# hive和apache-hive-3.1.3-bin目录修改归属用户
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive
cd /export/server/hive/
mkdir /export/server/hive/logs
# 启动hive
-- 元数据管理服务
# 前台启动
bin/hive --service metastore
# 后台启动
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
-- 启动客户端
# hive shell
bin/hive
# hive thriftserver方式
bin/hive --service hiveserver2
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
-- 启动beeline
bin/beeline